Section - 3 Explore the Data
3.1 Pull the Data
The first thing we will need to do is download the latest data. We will do this by using the pins package (Luraschi 2020), which has already been loaded into our session in the previous section.
First, we will need to connect to a public GitHub repository (as previously described) and register the board that the data is pinned to by using the board_register() function:
board_register(name = "pins_board",
url = "https://raw.githubusercontent.com/predictcrypto/pins/master/",
board = "datatxt")By running the board_register() command on the URL where the data is located, we can now “ask” for the data we are interested in, which is called hitBTC_orderbook, by using the pin_get() command:
The data has been saved to the cryptodata object.
3.2 Data Preview
Below is a preview of the data:
Only the first 2,000 rows of the data are shown in the table above. There are 300000 rows in the actual full dataset. The latest data is from 2023-08-26 (UTC timezone).
This is tidy data, meaning:
Every column is a variable.
Every row is an observation.
Every cell is a single value relating to a specific variable and observation.
The data is collected once per hour. Each row is an observation of an individual cryptocurrency, and the same cryptocurrency is tracked on an hourly basis, each time presented as a new row in the dataset.
3.3 The definition of a “price”
When we are talking about the price of a cryptocurrency, there are several different ways to define it and there is a lot more than meets the eye. Most people check cryptocurrency “prices” on websites that aggregate data across thousands of exchanges, and have ways of computing a global average that represents the current “price” of the cryptocurrency. This is what happens on the very popular website coinmarketcap.com, but is this the correct approach for our use case?
Before we even start programming, a crucial step of any successful predictive modeling process is defining the problem in a way that makes sense in relation to the actions we are looking to take. If we are looking to trade a specific cryptocurrency on a specific exchange, using the global average price is not going to be the best approach because we might create a model that believes we could have traded at certain prices when this was actually not the case. If this was the only data available we could certainly try and extrapolate trends across all exchanges and countries, but a better alternative available to us is to define the price as the price that we could have actually purchased the cryptocurrency at. If we are interested in purchasing a cryptocurrency, we should consider data for the price we could have actually purchased it at.
3.3.1 Order Book
A cryptocurrency exchange works by having a constantly evolving order book, where traders can post specific trades they want to make to either sell or buy a cryptocurrency specifying the price and quantity. When someone posts a trade to sell a cryptocurrency at a price that someone else is looking to purchase it at, a trade between the two parties will take place.
You can find the live order book for the exchange we will be using here: https://hitbtc.com/btc-to-usdt
From that page you can scroll down to view specific information relating to the orderbooks: 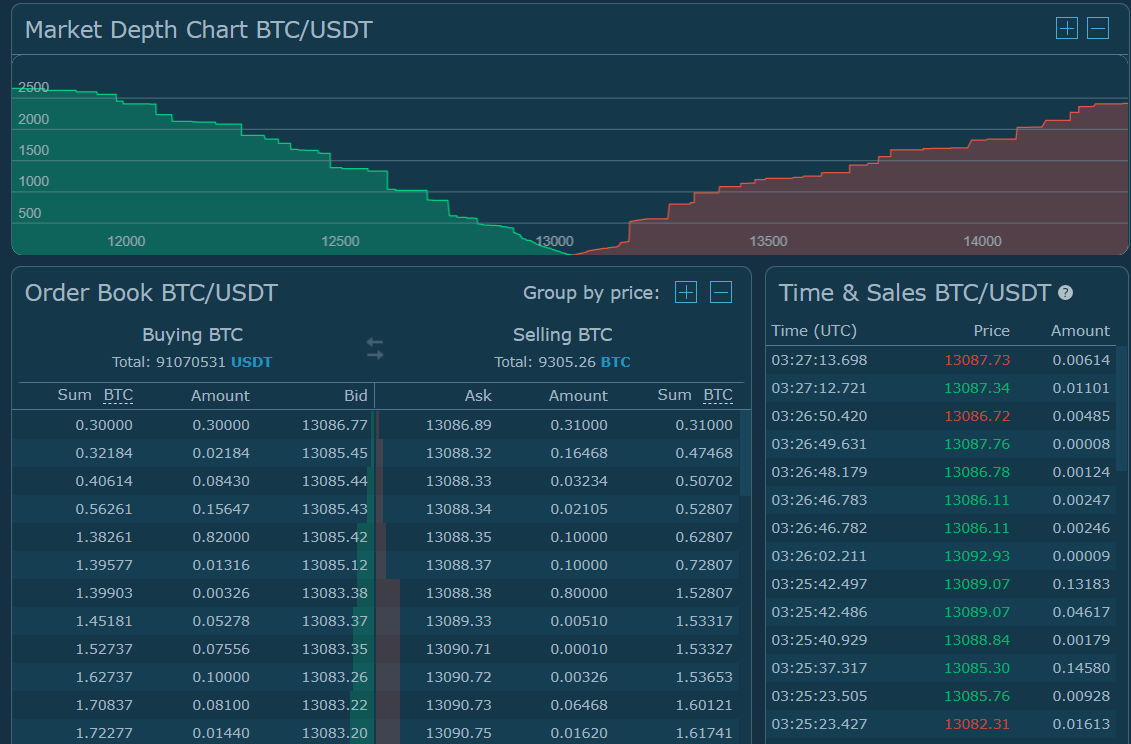
3.3.1.1 Market Depth
Let’s focus on the Market Depth Chart for now: 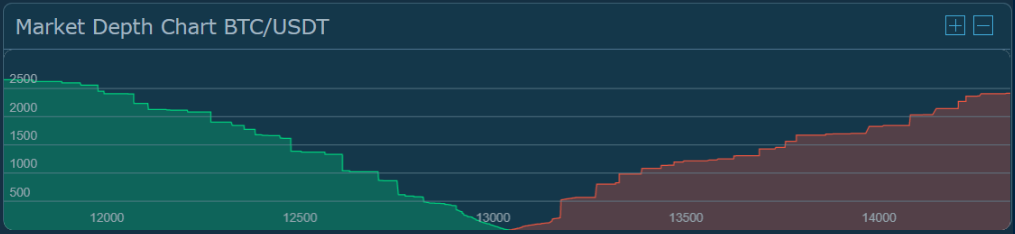
Here, the x-axis shows the price of the cryptocurrency, with the lower prices on the left and the higher ones on the right, while the y-axis shows the cumulative volume (here in terms of Bitcoins) of orders that could currently be triggered on each side (the “liquidity” of the market).
In the screenshot above, around the $13,000 price point the market essentially “runs out” of people willing to buy the cryptocurrency, and for prices past that point people are looking to sell the asset. The screenshot shows there are many orders that are waiting to be fulfilled, around the $12,500 price point shown for example the chart tells us that if we wanted to buy the cryptocurrency BTC at that price there would have to be about 1,500 BTC sold for more expensive prices before the order was triggered. The market will fulfill trades that are posted to the order book and match buyers and sellers. The price at which the two sides of the orderbook converge is the price we could currently trade the cryptocurrency on this exchange at.
Because the price works this way, we couldn’t simply buy 1,500 BTC at the $13,000 price point because we would run out of people who are willing to sell their BTC at that price point, and to fulfill the entire order we would need to pay more than what we would consider to be the “price” depending on how much we were looking to purchase. This is one of the many reasons for why any positive results shown here wouldn’t necessarily produce an effective trading strategy if put into practice in the real world. There is a meaningful difference between predicting price movements for the cryptocurrency markets, and actually performing effective trades, so please experiment and play around with the data as much as you’d like, but hold back the urge to use this data to perform real trades.
3.3.1.2 Live Order Book
Below the Market Depth Chart we can find the actual data relating to the order books visualized above:
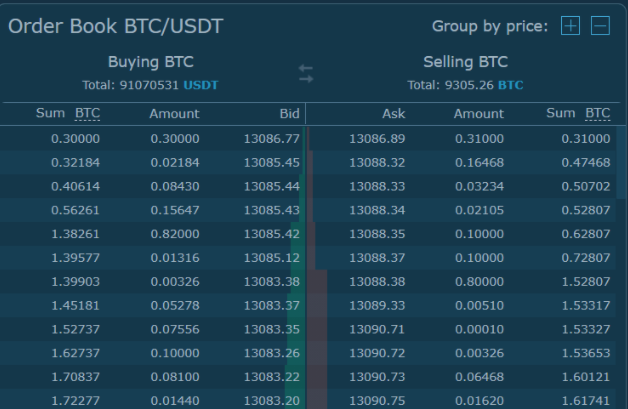
The data we will be working with is comprised by the top 5 price points of the order book on each side. We have access to the 5 highest bid prices (on the side looking to buy), and the 5 lowest ask prices (from traders looking to sell). In relation to the screenshot above, the data we are using would be made up of the first 5 rows shown only.
3.3.2 In Summary
To summarize the implications of what was explained above, the data we are using gives us the 5 nearest prices on both sides of where the red and green lines connect on the Market Depth Chart, as well as the quantity available to purchase or sell at that given price point.
In order to make predictive models to predict the price of a cryptocurrency, we will first need to define the price as the lowest available price that allows us to buy “enough” of it based on the current orderbook data as described above.
3.4 Data Quality
Before jumping into actually cleaning your data, it’s worth spending time doing some Exploratory Data Analysis (EDA), which is the process of analyzing the data itself for issues before starting on any other process. Most data science and business problems will require you to have a deep understanding of your dataset and all of its caveats and issues, and without those fundamental problems understood and accounted for no model will make sense. In our case this understanding mostly comes from understanding how the price of a cryptocurrency is defined, which we reviewed above, and there isn’t too much else for us to worry about in terms of the quality of the raw data, but in other cases doing EDA will be a more involved process doing things like visualizing the different columns of the data. There are a lot of tools that can be used for this, but as an example we can use one of the packages we already imported into the R session in the setup section called skimr (Waring et al. 2020) to get a quick overview/summary of the “quality” of the different columns that make up the data.
We can use the skim() function on the cryptodata dataframe to get a summary of the data to help locate any potential data quality issues:
| Name | cryptodata |
| Number of rows | 300000 |
| Number of columns | 27 |
| _______________________ | |
| Column type frequency: | |
| character | 5 |
| Date | 1 |
| numeric | 20 |
| POSIXct | 1 |
| ________________________ | |
| Group variables |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| pair | 0 | 1 | 5 | 10 | 0 | 301 | 0 |
| symbol | 0 | 1 | 1 | 6 | 0 | 301 | 0 |
| quote_currency | 0 | 1 | 3 | 3 | 0 | 1 | 0 |
| pkDummy | 0 | 1 | 13 | 13 | 0 | 1444 | 0 |
| pkey | 0 | 1 | 14 | 19 | 0 | 300000 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date | 0 | 1 | 2023-06-27 | 2023-08-26 | 2023-07-28 | 61 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| ask_1_price | 0 | 1 | 34082.17 | 5773468.90 | 0 | 0.01 | 0.17 | 1.00 | 999999999.00 | ▇▁▁▁▁ |
| ask_1_quantity | 0 | 1 | 29549593.53 | 480040972.05 | 0 | 11.99 | 293.18 | 4407.50 | 12589710000.00 | ▇▁▁▁▁ |
| ask_2_price | 0 | 1 | 334392.78 | 57734446.39 | 0 | 0.01 | 0.18 | 1.05 | 9999999999.00 | ▇▁▁▁▁ |
| ask_2_quantity | 0 | 1 | 36476282.22 | 605095921.55 | 0 | 17.30 | 512.12 | 5778.00 | 31100800000.00 | ▇▁▁▁▁ |
| ask_3_price | 0 | 1 | 3337581.29 | 577344471.63 | 0 | 0.01 | 0.19 | 1.10 | 99999999999.00 | ▇▁▁▁▁ |
| ask_3_quantity | 0 | 1 | 43190479.54 | 765210993.78 | 0 | 10.10 | 537.40 | 7309.10 | 31100800000.00 | ▇▁▁▁▁ |
| ask_4_price | 0 | 1 | 36101078.19 | 5775795002.62 | 0 | 0.01 | 0.20 | 1.21 | 999999999999.00 | ▇▁▁▁▁ |
| ask_4_quantity | 0 | 1 | 56539981.51 | 970372670.00 | 0 | 9.26 | 602.00 | 9540.00 | 37549725000.00 | ▇▁▁▁▁ |
| ask_5_price | 0 | 1 | 11360668159.65 | 1050338349892.28 | 0 | 0.01 | 0.20 | 1.35 | 99999999999999.00 | ▇▁▁▁▁ |
| ask_5_quantity | 0 | 1 | 36275963.68 | 796268560.13 | 0 | 8.40 | 630.74 | 10490.92 | 32108627000.00 | ▇▁▁▁▁ |
| bid_1_price | 0 | 1 | 170.58 | 2042.45 | 0 | 0.01 | 0.11 | 0.75 | 31590.29 | ▇▁▁▁▁ |
| bid_1_quantity | 0 | 1 | 28139429.80 | 517984715.32 | 0 | 15.00 | 444.10 | 6428.00 | 42557764000.00 | ▇▁▁▁▁ |
| bid_2_price | 0 | 1 | 170.07 | 2041.45 | 0 | 0.01 | 0.10 | 0.75 | 31588.72 | ▇▁▁▁▁ |
| bid_2_quantity | 0 | 1 | 27772295.82 | 500313671.74 | 0 | 23.34 | 555.00 | 9521.90 | 71250440000.00 | ▇▁▁▁▁ |
| bid_3_price | 0 | 1 | 169.74 | 2041.19 | 0 | 0.00 | 0.08 | 0.72 | 31588.71 | ▇▁▁▁▁ |
| bid_3_quantity | 0 | 1 | 48585460.94 | 782024519.12 | 0 | 20.00 | 719.65 | 11000.00 | 40883100000.00 | ▇▁▁▁▁ |
| bid_4_price | 0 | 1 | 168.63 | 2039.95 | 0 | 0.00 | 0.07 | 0.70 | 31588.70 | ▇▁▁▁▁ |
| bid_4_quantity | 0 | 1 | 56995698.93 | 941487861.87 | 0 | 26.67 | 909.00 | 14385.05 | 23320793000.00 | ▇▁▁▁▁ |
| bid_5_price | 0 | 1 | 166.43 | 2037.14 | 0 | 0.00 | 0.06 | 0.68 | 31586.96 | ▇▁▁▁▁ |
| bid_5_quantity | 0 | 1 | 60140986.01 | 1199002884.40 | 0 | 32.00 | 1000.00 | 15984.00 | 166599290000.00 | ▇▁▁▁▁ |
Variable type: POSIXct
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date_time_utc | 0 | 1 | 2023-06-27 | 2023-08-26 12:04:27 | 2023-07-28 02:01:33 | 231729 |
This summary helps us understand things like how many rows with missing values there are in a given column, or how the values are distributed. In this case there shouldn’t be any major data quality issues, for example the majority of values should not be NA/missing. If you are noticing something different please create an issue on the GitHub repository for the project.
One more optional section below for anyone who wants even more specific details around the entire process by which the data is collected and made available. Move on to the next section, where we make the adjustments necessary to the data before we can start making visualizations and predictive models.
3.5 Data Source Additional Details
This section is optional for anyone who wants to know the exact process of how the data is sourced and refreshed.
The data is pulled without authentication requirements using a public API endpoint made available by the HitBTC cryptocurrency exchange (the one we are using). See the code below for an actual example of how the data was sourced that runs every time this document runs. Below is an example pulling the Ethereum (ETH) cryptocurrency, if you followed the setup steps you should be able to run the code below for yourself to pull the live order book data:
fromJSON(content(GET("https://api.hitbtc.com/api/2/public/orderbook/ETHUSD",
query=list(limit=5)),
type = "text",
encoding = "UTF-8"))## $symbol
## [1] "ETHUSD"
##
## $timestamp
## [1] "2023-08-26T12:46:11.196Z"
##
## $batchingTime
## [1] "2023-08-26T12:46:11.280Z"
##
## $ask
## price size
## 1 1647.526 0.0668
## 2 1647.762 0.0360
## 3 1647.763 3.8745
## 4 1648.024 0.1579
## 5 1648.096 1.8364
##
## $bid
## price size
## 1 1646.929 0.6125
## 2 1646.395 0.2166
## 3 1646.394 0.1583
## 4 1646.366 0.1608
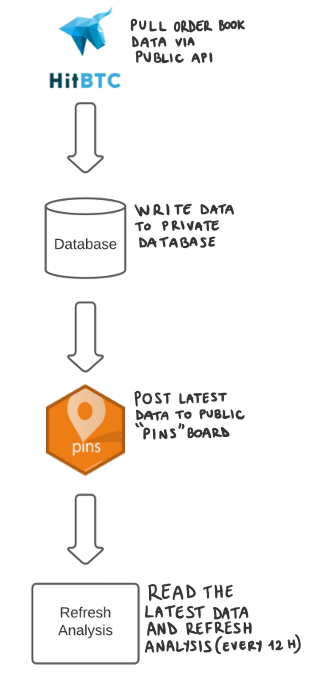
## 5 1646.229 0.4594The data is collected by a script running on a private RStudio server that iterates through all cryptocurrency options one by one at the start of every hour from the HitBTC cryptocurrency exchange API order books data (as pulled above), and appends the latest data to a private database for long-term storage. Once the data is in the database, a different script gets kicked off every hour to publish the latest data from the database to the publicly available pins data source discussed at the beginning of this section.
References
Luraschi, Javier. 2020. Pins: Pin, Discover and Share Resources. https://github.com/rstudio/pins.
Waring, Elin, Michael Quinn, Amelia McNamara, Eduardo Arino de la Rubia, Hao Zhu, and Shannon Ellis. 2020. Skimr: Compact and Flexible Summaries of Data. https://CRAN.R-project.org/package=skimr.